
Antes se pensaba que cuanto más contenido indexaban los motores de búsqueda de mi web, mejor. Ahora, nos hemos dado cuenta de que eso no es así, sino que es mejor que indexe únicamente contenido de calidad.
Entonces… ¿Qué pasa si no quieres que indexen todas las páginas de tu web o blog? Pues existen 2 opciones. La primera es utilizar una etiqueta especial en cada página (Meta Robots) y la otra, usar un archivo para controlar la entrada de los robots. Éste es el archivo robots.txt, y es el que vamos a ver en profundidad en este artículo.
¿Qué es el robots.txt?
Robotx.txt es un archivo de texto que una vez subido a nuestro sitio web, informa a los buscadores sobre qué partes del sitio no queremos que sea rastreadas.
Existen muchas ideas equivocadas sobre los archivos robots.txt. De hecho, en muchos sitios te dirán que gracias al archivo robots.txt evitarás que una parte de tu web sea indexada. Sin embargo eso no es del todo cierto.
Si lo que estás bloqueando es una página, estarás bloqueando su rastreo a las arañas o crawlers de los buscadores, pero no evitarás su indexación. Si otras páginas apuntan a la tuya con texto descriptivo, es posible que se indexe tu página.
Sin embargo, si lo que estás bloqueando son imágenes, vídeos o audios, evitarás ambas cosas. Es decir, que sea rastreado e indexado.
[elementor-template id=»9721″]
Así todo, el archivo robots.txt no puede forzar el comportamiento de un rastreador, sino que solo sirven como indicaciones para los mismos.
Cabe decir que su existencia no es obligatoria. Si no subimos ningún archivo robots.txt a nuestro sitio web o subimos uno que no tenga el formato adecuado, los bots entenderán que tienen acceso libre a toda la web.
Además, hay que tener en cuenta que el robots.txt solo funcionará en el dominio en el que se encuentre alojado. No funcionará con los subdominios que creemos y tendremos que generar un nuevo robots.txt para cada uno de ellos.
¿Cómo crear el archivo robots.txt?

Para crearlo, basta con abrir un bloc de notas y escribir las directrices. El archivo tiene que tener exactamente como nombre “robots.txt” y tiene que ser subido en la raíz del dominio. Si tienes tu web hecha con WordPress y usas Yoast, también tienes una apartado para crear tu robots.txt. Aprende cómo hacerlo en el tutorial de Yoast que tengo preparado.
Antes de ver cómo debemos informar a los rastreadores de qué zonas de la web pueden y no pueden rastrear, veamos las reglas que debemos tener en cuenta.
• Debes respetar las mayúsculas/minúsculas, la puntuación y los espacios.
• Cada grupo de User-agent/Disallow debe ser separado por una línea en blanco. En caso contrario se entenderá que las directivas son de aplicación a todos ellos.
• Podemos incluir comentarios usando la almohadilla “#” al comienzo de una línea.
Además, podremos utilizar dos expresiones regulares para identificar las páginas o subcarpetas que deben respetar las directivas de nuestro archivo:
- El asterisco (*): Es un comodín que representa cualquier secuencia de caracteres. No es necesario usarla al final de cada línea.
Por ejemplo:
/*.pdf nos estaremos refiriendo a cualquier archivo pdf
- El símbolo del dólar ($): Indica que la URL o archivo que estamos indicando en la directiva tiene que terminar forzosamente de la forma indicada.
Por ejemplo:
/*.pdf$ nos estamos refiriendo a todos los archivos que terminen en .pdf. Es decir, si nos encontramos con un archivo .pdf?ver=2.0, éste no entraría dentro de la directiva.
Dicho esto, veamos cómo podemos indicar a los rastreadores qué partes de nuestra web pueden y no pueden rastrear.
User-agent
Cuando empezamos a crear nuestro archivo robots.txt lo primero que tenemos que tener claro es a qué bots o rastreadores nos estamos dirigiendo. Para indicar a que rastreador se dirigen las directivas, tenemos que usar el “user-agent”.
De esta forma, si ponemos en el archivo robots.txt lo siguiente:
User-agent: * → indicará que las directivas están dirigidas a todos los rastreadores
User-agent: googlebot → indicará que las directivas están dirigidas al rastreador googlebot
Y así sucesivamente con todos los bots a los que nos vayamos a dirigir.
Directiva Disallow

Esta directiva nos permite decir a los rastreadores que no rastreen una página o archivo. Ojo, porque le decimos que no rastree, no que no indexe.
Los buscadores serán capaces de indexar la página o archivo, pero como no son capaces de rastrearla no sabrán qué información contiene. Por lo que el snippet que nos muestre puede salir con el siguiente mensaje: “No hay disponible una descripción de este resultado debido al archivo robots.txt de este sitio.”
Veamos cómo funciona la directiva “Disallow”. Por ejemplo si en nuestro robots.txt ponemos:
User-agent: *
Disallow: /
Estaremos bloqueando el rastreo de todas las páginas y archivos de nuestro sitio a los bots de todos los buscadores.
User-agent: *
Disallow: /category/
Estaremos bloqueando el rastreo del directorio “category”. El resto de la web y archivos serán accesibles a los rastreadores de los buscadores.
Con la directiva disallow debemos tener cuidado ya que podemos estar bloqueando a los robots a rastrear zonas que realmente deberían rastrear.
La mejor manera de saber si estamos bloqueando a los rastreadores de Google es mediante la herramienta Google Search Console y su probador de robots.txt.
Además, en Search Console también podremos saber si lo que estamos bloqueando puede estar perjudicando a nuestro posicionamiento web.
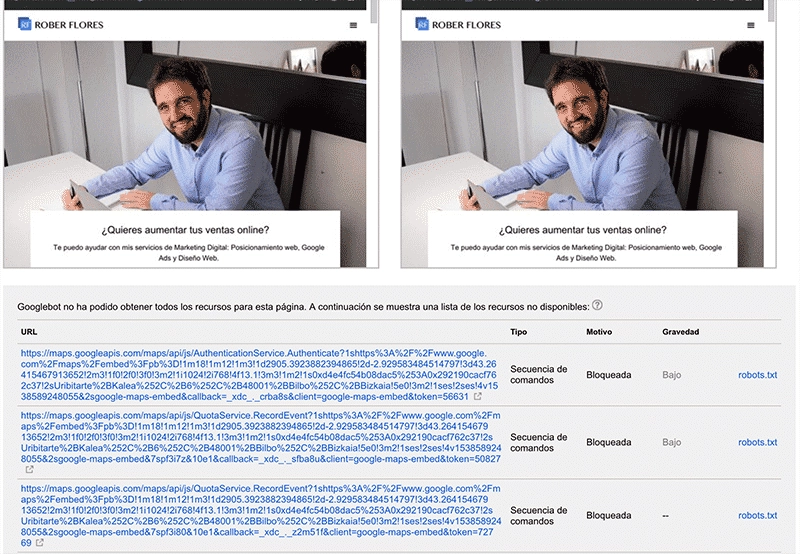
Si usamos la opción explorar como google y una vez explorado pinchamos en la propia dirección para ver como la ve Google y como la ven los usuarios, debajo nos marcará los elementos a los que los robots no han podido llegar por estar bloqueados y si es grave o no que estén bloqueados.
Directiva allow
Aunque por defecto los bots de los buscadores pueden rastrear la totalidad de la web, con la directiva allow podremos decirles qué partes queremos que rastreen.
Como por defecto ya hemos dicho que todo es rastreable, usaremos esta directiva únicamente cuando hayamos usado la directiva disallow en alguna parte de nuestra web, pero queramos que pueda acceder a otra parte contenida dentro de esa parte bloqueada.
Por ejemplo, imagínate que queremos bloquear la carpeta de plugins de WordPress, pero queremos que los CSS y javascript de esa carpeta las puedan rastrear. Lo haríamos de la siguiente forma:
User-agent: *
Disallow: /wp-content/plugins/
Allow: /wp-content/plugins/*.css
Allow: /wp-content/plugins/*.js
Otras directivas
Además de las directivas disallow y allow también podemos encontrarnos con otras directivas dentro del archivo robots.txt.
Entre ellas se encuentra la directiva sitemap. Con ella le diremos a los bots dónde se encuentra nuestro sitemap y facilitaremos el rastreo de nuestra web.
También existe la directiva Crawl-delay, con la que limitaremos la velocidad de rastreo de nuestra web. Aunque Google bot la ignora por completo, los crawlers de otros buscadores como Bing o Yandex sí que la tienen en cuenta.
Como puedes ver el archivo robots.txt es una herramienta muy potente y que si la usamos correctamente nos va a permitir guiar a los rastreadores de los buscadores a lo largo de nuestro sitio web.
Además, gracias a este archivo evitaremos que los bots pierdan tiempo rastreando recursos que no sean relevantes y conseguiremos que dediquen su tiempo a rastrear las partes realmente importantes.
Si quieres más información sobre el robots.txt, te recomiendo que eches un vistazo en el enlace al soporte de Google que te dejo a continuación. https://support.google.com/webmasters/answer/6062608?hl=es
Y recuerda, si necesitas ayuda con el posicionamiento web no dudes en contactarnos.



Muy buena explicación. Gracias Roberto. Entiendo que de forma predeterminada los links son follow.
Muchas gracias Sergio. Sinceramente, no he llegado a entender tu duda, ¿podrías replantearla por favor?
Quería decir allow, que ando dormido. Si no pones nada es como poner allow? Cual es la función de poner entonces urls con allow? O no ed necesario poner nada en realidad?
Ah ok, no te preocupes. La etiqueta allow resulta útil cuando quieres indexar un directorio o archivo específico de un directorio al que anteriormente has denegado su acceso. Es decir, si tu tienes por ejemplo, Disallow: /wp-content/ pero quieres que se indexe el directorio wp-content/uploads lo pones en el archivo robots.txt con la etiqueta allow, Allow: /wp-content/uploads. No se si me explico, funciona cómo etiqueta para eliminar restricciones ya existentes.
Si por el contrario no tienes denegado el acceso anteriormente a wp-content, es como si no pusieras nada.
Un saludo Sergio, espero que te haya servido la explicación.
Que bueno, tengo que probarlo yo también. Gracias por el aporte.
Hola, gracias por la aportación.
Solo una pregunta. ¿Se puede poner una lína disallow, otra allow y otra disallow?
Disallow: /wp-admin/
Allow: .js
Allow: .css
Disallow: /feed/
Hola Samuel, sí se puede. Un saludo
Un post genial, me ha sido muy útil saber qué es el robot y sus funciones. Tus post son de gran ayuda para los que comenzamos en el seo.
Muchísimas gracias May, me alegro de que te sirva de ayuda 😉
Un abrazo!!